

Our customers go serverless for live locations with HyperTrack. They use us as a managed service for live locations. They do not need to build and manage the servers to ingest, process, store, provision and manage anything related to the live location of their app users.
Turns out, we practice what we preach!
We go serverless for our platform with AWS. For ingesting the data streams from our SDKs, processing them for accuracy, making locations available for real-time features, and persisting data in our data lake for analytics & machine learning; we leverage Amazon Web Services through a serverless architecture.
In this blog, we give you a peek under the hood and share our learnings.
Motivation
HyperTrack is a self-serve platform for live location in the cloud. Tens of thousands of developers from around the world are on the platform. Developers add our SDKs in their apps to start tracking. At first, they use this data to build features in a test environment. After the test, the app is rolled out to users at large. HyperTrack customers pay-per-use, retain full control over ramping their usage up or down and expect that it just works.
In turn, we need to build a system that can scale up and down automatically, without any engineering interventions. We do not have the luxury to forecast, manually provision or de-provision services, or get insights into our customers' roll-out cycles across 22 time zones. Furthermore, the services need to have low latency responses, real-time processing, a highly available platform, and reliable infrastructure.
Serverless for the win! The AWS components we use are designed to auto-scale and require no operations or administration efforts.
Day in the life of a location
HyperTrack tracks app users on the move. Let us track the life of a single location on the move inside our serverless platform. First, let's look at the auth, ingestion and processing parts:
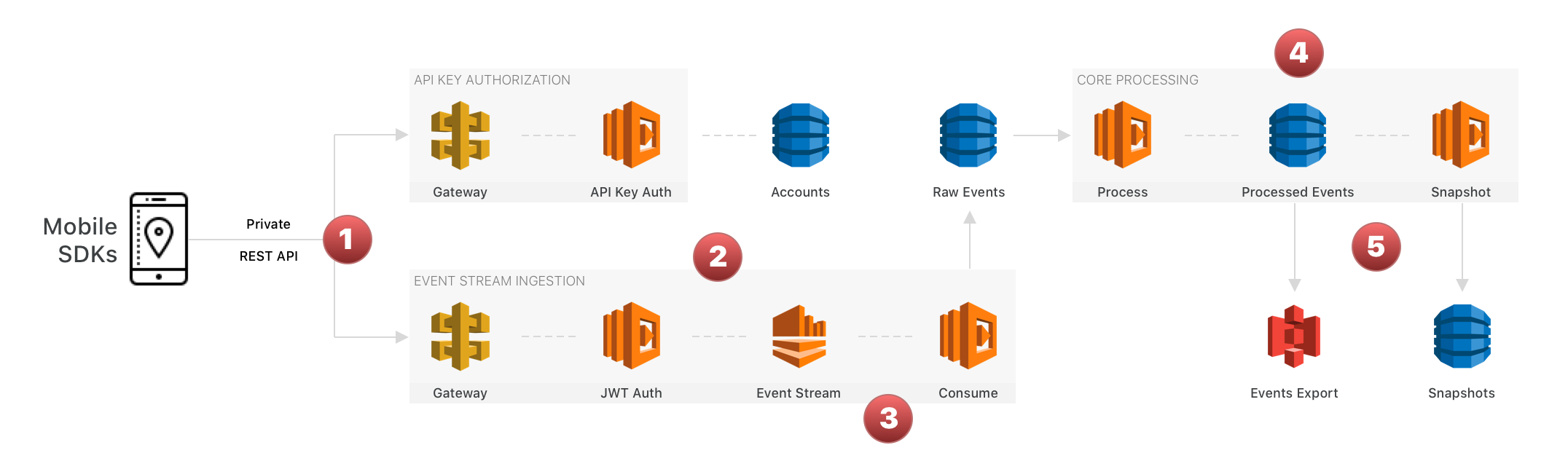
1. HyperTrack SDKs within customer apps send locations and associated context (activity, permissions, battery, etc.) to the HyperTrack ingestion pipeline via HTTP post requests.
2. API Gateway endpoint receives location events, checks the authorization headers and puts the data record on our main Kinesis stream
3. Kinesis reliably buffers the data, decouples our endpoint from processing resources and makes it available for real-time processing
4. Lambda functions of various shapes and sizes are invoked by Kinesis, DynamoDB streams or other lambdas to process the locations for accuracy, filter the noise and transform the data for upstream interfaces and applications
5. DynamoDB stores real-time location only, archives useful locations to S3 for future use, and discards the rest
Now, let's review how we leverage the stored and archived data to expose it to our developers:
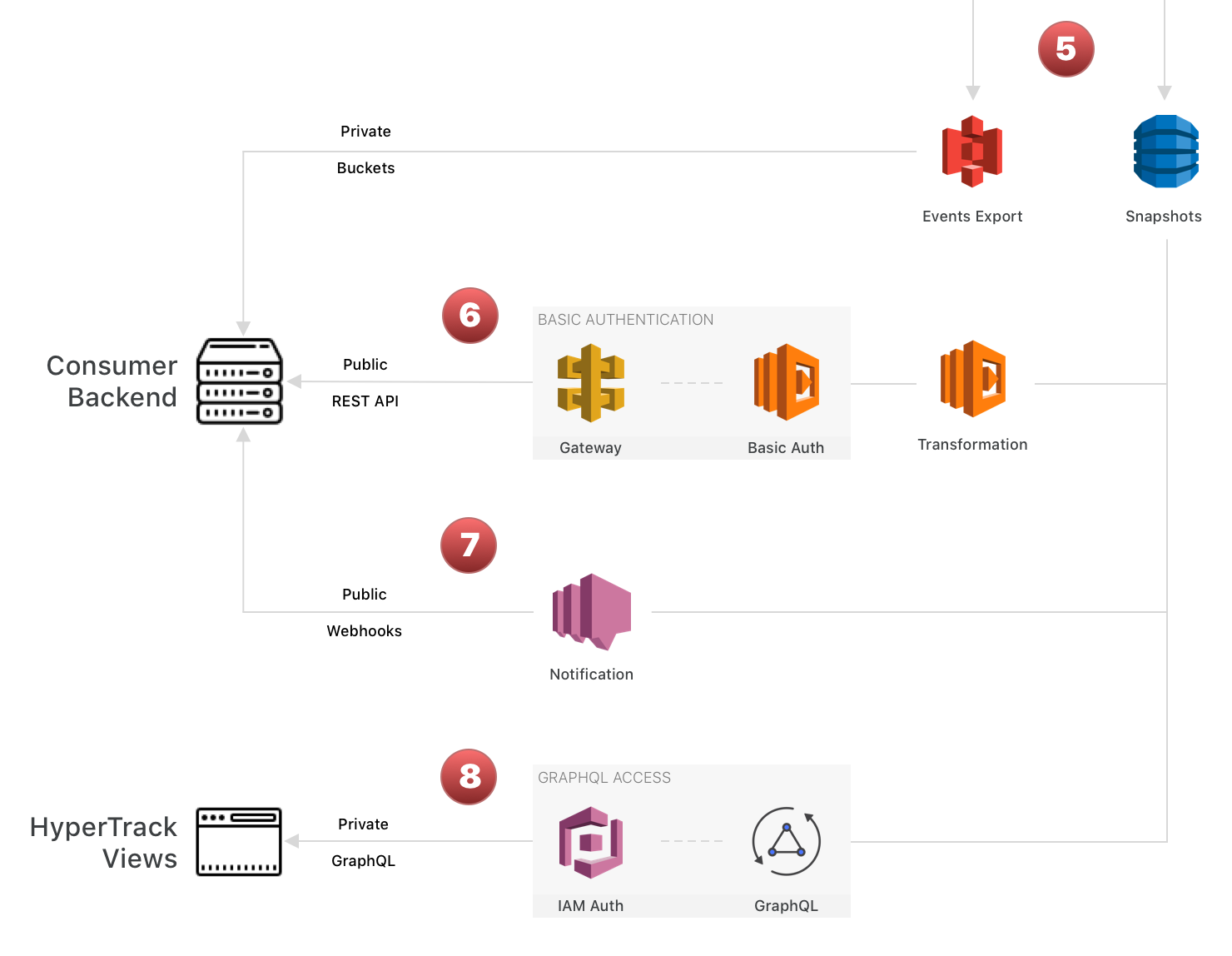
6. Location, context, and device data is transformed into a JSON format and exposed through public REST APIs. Access to these endpoints is controlled with Basic access authentication
7. AWS SNS verifies subscriptions and handles Webhook dispatching
8. AppSync serves GraphQL endpoints for various web and native front end applications to consume through queries and subscriptions. Access to these endpoints is controlled by AWS Cognito
The proof is in the pudding
“In theory, there is no difference between theory and practice. In practice, there is.”
We stress-tested the platform before proudly announcing it to the world. All was well.
Waking up with customers in different time zones complaining about API latencies and degrading performance had become a thing of the past. Costs were well in control and the pay-per-use pricing turned out a great fit for us. The first few spikes on the new version hosted on the serverless platform were handled gracefully and did not burn a hole in the pocket. The administration and oversight required were at a bare minimum as well.
And then one fine morning, life got interesting…
All hell broke loose on our monitoring dashboard. All numbers were off the charts. API pings, devices, events, authorizations, you name it!
Requests to one of our APIs peaked at around 10k requests/second:
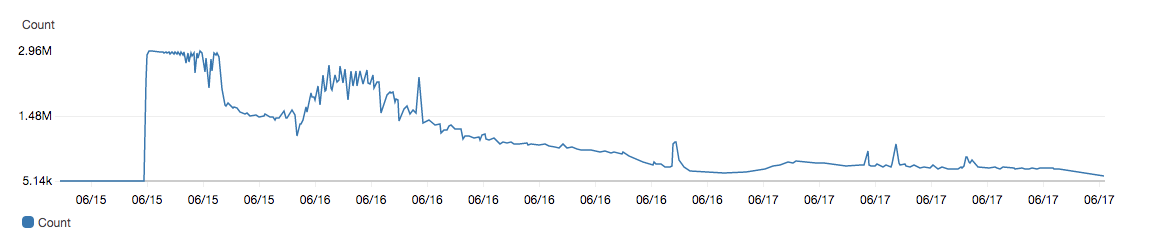
The good news was that API latencies, uptime, and real-time performance were normal. The serverless architecture had scaled up automagically to handle the traffic that was 2-3 orders of magnitude higher than the day before. However, you did not want the CFO to see this.
A leading consumer app in the travel space had launched a ride-sharing service in their main app. The service was launched in just three cities as a test, yet that amounted to millions of devices registering with HyperTrack servers in the first few days.
Due to a benign integration bug, device registrations were happening at app launch rather than when tracking was to start. Our platform dealt with these events similarly as location time series, and that bombarded our real-time data pipe.
Although inadvertent, it was an awesome stress test of our serverless architecture. We were proud that systems held up and all pipes and connectors handled the river that suddenly starting flowing through them. It gave us high confidence in our ability to scale it up for the ocean to flow through it one day.
Infrastructure-as-Code and Continuous Integration and Deployment
The benefits of the serverless pattern are striking, and we found ourselves quickly using it across our platform. Now we are running hundreds of Lambda functions, store data in almost as many DynamoDB tables and leverage dozens of other Amazon services to make our platform work across our environments.
The complexity of managing the high number of resources and wiring them up with each other is only manageable through strong automation. And defining all the infrastructure-as-code is critical to achieving that automation. Luckily we are all strong believers in automation and built HyperTrack with IaC from the beginning.
We started with Terraform to define all of our resources using configuration files. Terraform was picked because of the open source nature with strong community support. It helped that some of us used it before for other projects. Terraform is amazing for defining shared and static infrastructure. On the other hand, having to define each resource individually is too verbose (see HashiCorp tutorial) and gets in the way of iterating quickly on product features. Informed by this learning, we moved to Serverless framework for non-shared infrastructure parts.
Serverless is another open source tool with strong adoption and is focused on simple developer experience. Adopting that framework cut down the number of custom automation scripts and boilerplate code. Platform engineers were able to move faster and maintain code base easier.
Serverless services often need to know about shared resources deployed by Terraform. To support this, we write resources from Terraform to AWS Systems Manager (SSM) and read SSM from Serverless. Similar to the pattern described in this blog from Serverless.
For Terraform infrastructure, developers are running Jenkins jobs to deploy changes. Before applying the infrastructure changes, we dry-run Terraform (“terraform plan”) to understand what resources would be added and removed without making any actual changes. This process reduces the risk that shared and critical infrastructure will be destroyed, or otherwise impacted, but requires extra engineering oversights.
For all other services, we are using CircleCI to build, test and deploy continuously. It’s another way to go serverless for CI/CD–achieving full automation without having to maintain your own infrastructure. Furthermore, we have seen great success in allowing platform engineers to iterate more quickly.
Sharing with community
In our post about the HyperTrack culture a few weeks ago, we mentioned radical openness as one of our four values because we value trust with our team, community, and customers–“...Within the community, we are as open as support groups dealing with similar problems would be. With customers, we are as open as colleagues working on the same project would be. Our product stands for openness between our customers’ team and users.”. In this spirit, we are sharing this post with the developer community at large.
Conclusion
Serverless is awesome! If you are in the business of pay-per-use software or services, it is a no-brainer. Just as you want your customers to stop making fixed cost investments and trust you with their business, you need to trust cloud-based managed services with yours.
We would love to hear your thoughts and answer your questions. Please let us know which topic you would find most useful for us to dive into, and we might just follow it up with an in-depth blog on it.
We are looking to hire awesome engineers in the team in San Francisco. Look us up and say hi!

