

This is part three of a ten part series about building movement-aware applications. In the previous parts, we talked about the challenges in generating movement data from the OS and then ensuring accuracy. In this part, we will talk about making movement data available for consumption in real-time. We will talk about use cases that need real-time data and hurdles we need to overcome to deliver that.
Introduction
Imagine if it took half a minute to generate the receipt for your Uber ride. Both driver and rider would get impatient. The driver would start losing patience with every extra second to complete the ride in the app before servicing the next customer. The rider would lose patience if she wants to confirm the amount before exiting the cab or has chosen to pay cash. Thirty seconds is an eternity in a real-world product experience.
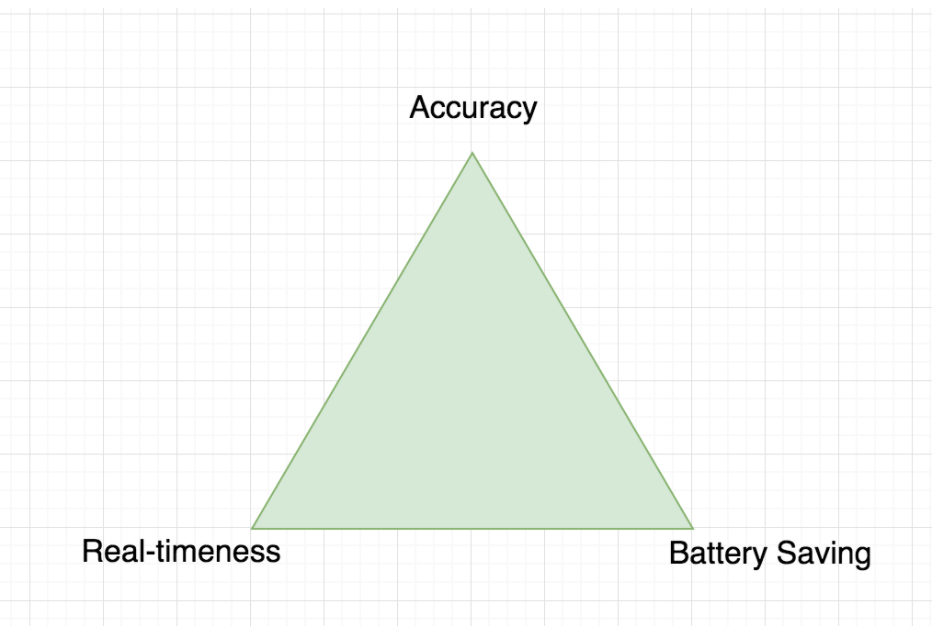
The previous part talked about the BAR principle of movement—that it is extremely difficult to simultaneously provide more than two out of the following three—Battery, Accuracy and Real-timeness. A system that optimizes for high accuracy and real-timeness will drain battery. Maximizing accuracy while minimizing battery will lose real-timeness of data on the server. Optimizing for real-timeness and saving battery will compromise accuracy.
Designing a stack that generates, manages and consumes movement data in real-time has multiple challenges and requires an integrated approach. Movement data is generated from the various sensors on the device, managed on the server with real-time processing, and then consumed on clients as data, visuals or events. These clients might be native apps, hybrid apps, web interfaces, dashboard widgets or web services that deliver real-time use cases. Separately building the components on the device, server and client, and then cobbling them together will deliver a non-performant stack.
In this article, we will talk about use cases that require real-timeness of movement data, challenges in building a stack that delivers it, approaches to address those challenges and design considerations for real-time user experiences.
Real-time use cases
Here are a few examples of use cases that require movement data in real-time.
- Movement-based alerts: Developers want to build applications to notify users, customers or operations teams based on speed, mileage, activity change, long stops, route deviations, geofences and many more inferences using movement data. Sophisticated applications might trigger other business workflows to proactively take actions based on this data. These alerts must trigger in real-time for them to be meaningful. Delayed events might trigger incorrect communication and workflows.
- Mileage tracking: Developers want to generate bills and receipts based on the actual mileage of a ride immediately after it ends. Some apps want to notify customers immediately when mileage-based billing exceeds the authorized threshold. Accurate mileage needs to be delivered in real-time in these cases.
- Order tracking experience: An ever-growing list of apps involving product or service delivery want to track the movement of the order in real-time. Customers and operations teams consume this data through various interfaces. Live location, live activity and device health help these consumers get better visibility, especially when things go awry. Furthermore, developers want to build beautiful tracking experiences in their products with smooth animations, polylines, bearing, live tickers for ETA/distance, and other such enrichments in real-time.
- Safety: SOS calls, ambulances, school buses and other safety use cases want accurate live location and activity in real-time to save the day.
- Live location sharing: With Whatsapp, Google Maps and Facebook Messenger offering this functionality in their core feature set, many other consumer apps want to build a similar feature. Messengers want to enable friends and colleagues to share live location with each other when on the way to meet up. Marketplaces want to enable buyers and sellers to share live location with each other when on the way to consummate a transaction. These experiences must deliver real-time movement data at a massive scale.
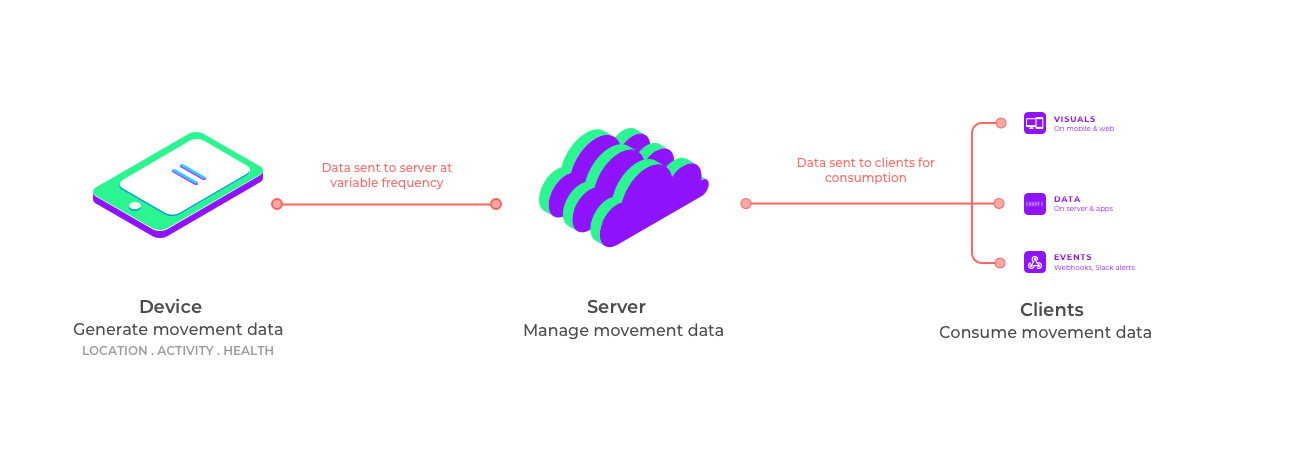
In a real-time location tracking app, the data flows from the devices up to the server back down to the clients for consumption as data, visuals or events. Each layer in this stack imposes challenges which we will now discuss.
Ingesting data in real-time from device to server
Challenges
In part one, we talked about the types of movement data generated on the device and provided by the OS to apps. We explained how the APIs offered to developers are significantly restricted in comparison with the movement features built by the OS for its own device users. This means that we need a non-trivial device-to-cloud stack to process raw event data and bring these features to life. This is not going to come from OS because of privacy concerns. We need a mechanism to continuously beam data from device to server in batches.
On the device, the GPS sensor takes time to wake up and get a fix. This is because GPS must have three sets of data before it can provide accurate position: GPS satellite signals, almanac data, and ephemeris data. If a GPS is new, has been turned off for a long period of time or has been transported for a long distance since it was turned on, it will take longer to acquire these data sets and get a Time to First Fix (TTFF). GPS manufacturers use various techniques to speed up TTFF, including downloading and storing almanac and ephemeris data via wireless network connections (faster than acquiring via satellite). A cold start refers to a situation in which the GPS must acquire all data in order to start navigation and may take up to 12 minutes. A warm start means the GPS has most of the data it needs in memory, and will start quickly—a minute or less.
The first few locations are often noisy. So we need to collect multiple data points over time to provide accurate location. Similar challenges and idiosyncracies exist for activity sensors.
On the server, this poses some challenges as the scale grows. Use cases like order tracking and live location sharing need real-time data streams or On-Line Transaction Processing (OLTP), while analytics and machine learning models need relatively sparse data or On-line Analytical Processing (OLAP).
The growing size of data is another challenge. If you’re tracking 1,000 devices for 10 hours a day with data collection every 5 seconds, this adds up to ~7 GB of raw data each day, assuming a 1KB packet containing location, activity, health and route data. It is non-trivial to manage efficient storage and processing of this volume of data, especially when it enables both transactions and analytics.
The events must also be sent in a synchronized manner. If data arrives out-of-order on the server, it can cause problems like misfiring of events. Out of order events become part of processing and need to be handled when they arrive late at the server. This leads to synchronization issues in the processing pipeline.
Approaches
Building an ingestion service is the first step in real-time data processing. A real-time processing pipeline needs a very quick ingestion pipeline. When you have millions of movement events coming to your servers from mobile devices, handling latencies at the ingestion pipeline becomes a challenge. A streaming architecture is recommended for such a pipeline where millions of events are consumed in a stream and consumers process them as they come. This reduces the latency as you do not need to persist events in any datastore at the time of ingestion.
The two popular choices for data streaming are Kinesis and Kafka. Kinesis is a fully managed and hosted solution on AWS while Kafka is an open source data stream solution. In some performance metrics, Kafka outruns Kinesis. But there are many more factors and the choice between them depends on your company’s size, stage and priorities. If you are willing to invest in maintaining and tuning the performance of your own data stream, then you can go with Kafka, else Kinesis is great. Both of them can capture and store terabytes of data per hour from hundreds of thousands of sources.
Processing data for accuracy
Challenges
Once movement data is ingested from the device to server in real-time, it needs to go through a processing pipeline for improving accuracy and adding enrichments.
Such a processing pipeline involves multiple stages. Noise filtering removes outliers based on location and speed. Duplicate events are removed and de-clustered. Activity segments are merged, split or re-calibrated with more context from other data sets. Map matching ensures that location points correspond to roads, routes and places on the map. We talked about improving accuracy using map context, device health context, and activity context accuracy in part 2.
For geocoding and reverse geocoding, we need to access external systems via APIs which can add ~200ms of delay. Same is true for ETA fetches that might require accessing systems like Google Maps, Mapbox or HERE Maps that incorporate real-time traffic data, speed limits and other factors to power drive ETAs.
All of this server-side processing including a low latency ingestion and processing pipeline takes around 1 second, so we can see a clear tradeoff between accuracy and real-timeness. The more time you spend processing the data, the longer the user has to wait.
Approaches
When movement data is being processed on the server, some stages may be postponed or skipped for improving real-timeness. For example, accurate distances, routes taken and expected routes need not be computed when friends are sharing live location with each other. Map matching may be skipped for walks. Drive ETAs may be extrapolated using activity and speed with infrequent recalibrations with high-latency third party APIs.
Serving data fast to the consumer in realtime is also very important. Storing data in cache (like Redis or Memcached) which is needed for real-time consumption and serving from it instead of database (like PostgreSQL) is a key approach. It keeps the latency of API response low and lets consumers view the data as soon as possible. This works because databases have to deal with integrity checks, persistence and replication whereas caches simply serve the data out of RAM. Using an optimized cache can improve read performance by as much as 100X.
When using a cache, we need to think carefully about eviction policy—which data to remove when new data needs to be stored in the cache. A few options are: (a) Least Recently Used (b) Least Frequently Used (c) First In, First Out, among others.
In certain cases, it is also possible to automatically take action in the application when a predetermined condition is met, such as user entering or exiting a geofence, time elapsed from the time another action started, or a set time like the end of a work day. Providing rule-based creation and completion of actions in the application helps make progress without user intervention.
Establishing connection from server to device in real-time
Challenges
The server needs to have the ability to reach devices on-demand and dynamically control the frequency of collecting and transmitting movement data. This requires reliable communication between the server and devices. This can be quite tricky on mobile platforms for various reasons:
- Device is offline: If the device is not connected to the Internet, the application should store the data on the device and transfer it when the connection is re-established. The server needs to fill up this data depending upon the client timestamp.
- App is killed by the OS or user: In iOS, the OS notifies the apps with location updates while running in the background, unless it is explicitly killed by the user. While in Android, if the Service is killed by the OS, the app is removed from the recent app list, or the OS assumes you have returned START_STICKY from onStartCommand(); then Android will restart your Service. In such cases, either the server can send a push notification to ask the user to open their app (unless the app was force-stopped) or the app can register for broadcast listeners.
- Throttling for notifications: For iOS, APNS takes into account battery consumption history of the app and accordingly limits the rate of notifications. For Android, there is a limit of 1,000 registration tokens per send when using registration_ids as parameter. So if you want to send 5,000 messages to different users, you'll need to send the message in 5 batches.
Approaches
It is important for the server to be aware of the device's connectivity status. This is usually implemented as a heartbeat—a periodic signal sent from the device to the server. The heartbeat frequency is typically higher than the transmission frequency of movement data. Absence of this heartbeat signal can be treated as network disconnected.
Since the heartbeat signal is so critical, it is often advisable to have multiple means of delivering it with fallbacks. If the app is awake, it can periodically send the heartbeat as a background service. If the app is suspended by the OS, the server can send a periodic push notification to wake the app up. This type of hybrid scheme often increases the reliability of heartbeat which in-turn helps with real-timeness.
Because the transmission frequencies for actual data can be very different from heartbeat, and can also dynamically change, it to separate these two streams on the device.
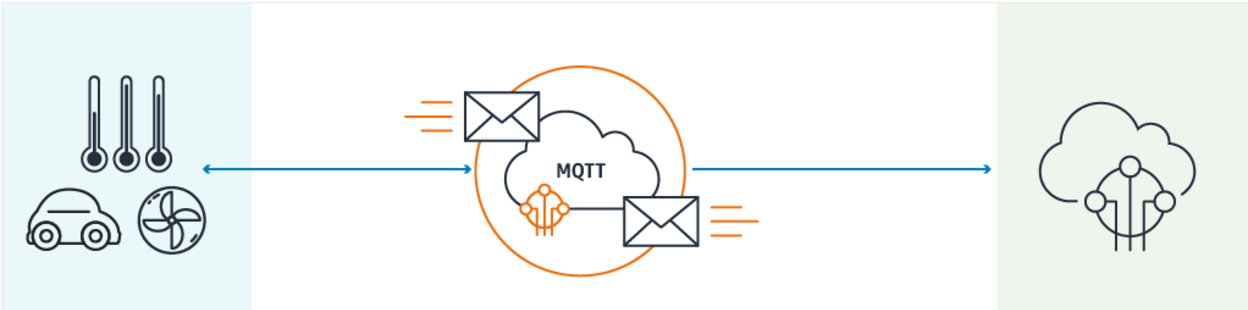
For the transport protocol, HTTP is very popular and widely used. But over past few years, MQTT has rapidly gained traction. MQTT, by being data-centric as opposed to being document-centric like HTTP, offers several advantages—making it suitable for bandwidth or battery constrained devices. According to this source, MQTT, when compared with HTTP:
- Has 93 times higher throughput
- Requires almost 12 times less battery power to send data
- Requires 170 times less battery to receive data
- Has 8 times less network overhead
- Has very short message headers (2 Bytes) where as HTTP can run into hundreds of Bytes before data transmission even begins
For these reasons, most real-time cloud platforms like AWS IoT have converged on using MQTT as their preferred transport protocol.
Dynamically adaptive generation and consumption of data on device
On the devices, collecting data or transmitting data at higher frequency increases the battery consumption. After a point, users will start noticing this battery drain and might turn location or activity permissions off, if not uninstall your app. Here we can see a clear tradeoff between battery and real-timeness. There is no universally perfect balance to optimize for battery or accuracy. The right balance varies from one app to another, and within one app, varies from one use case to the other.
For example, a user’s device would need to aggressively transmit movement data when someone is actively tracking user movement and could switch to a more conservative transmission without losing accuracy when no one’s watching. HyperTrack has a pending patent on a method that is specifically based on this intuition. In another example, a field agent with low battery might continue to have a high collection frequency but low transmission frequency.
The controls for collecting and transmitting movement data might vary based on device or consumption context. Investing in a stack that allows the server to vary such controls seems worthwhile but can be complex to implement.
Fundamentally, the idea is that data collection and data transmission on device should be driven and controlled by use case. At HyperTrack, we wrote a decision-tree based rule-engine on the device that accepts rulesets from the server in real-time.
User Experience
Real-time systems require us to follow certain design principles when building product experiences. We found this article to be a good starting point. In summary:
- Be state-aware: At all times, the user should know the state of the system. The product should communicate what’s happening and confirm user action. Users get frustrated when the state is opaque to them. Users can be surprisingly tolerant if they know that the system is listening and cares about their goals.
- Expect change: The user should know what to expect. The product should communicate what will happen when a user acts. When state can change drastically and frequently, we should foreshadow the result of actions. Giving users the opportunity to process what’s going to happen prevents surprises.
- Preserve context: The user should know where content comes from and where it belongs.
Conclusion
Balancing battery, accuracy and real-timeness is a complex problem that requires software on the device, in the cloud and map interfaces. Challenges for real-timeness exist at each layer of this stack—data collection on device, processing on server and consumption on clients through data, visuals and events.
These challenges become easier to solve by taking an integrated approach where these three layers working in tandem with each other. Neither the Operating Systems nor mapping providers are well equipped to solve this for you. It becomes imperative to build and manage a service that makes these systems dance together in real-time.
Previous: Part 2—Accuracy
Next: Part 4—Battery

