
This is part two of a ten part series about building movement-aware applications. In the last part, we spoke about the role of the smartphone OS in generating movement data using various device sensors. In this part, we will talk about the work needed to get accurate movement data for consumption in use cases.
Introduction
The OS generates movement data in two primary parts—location and activity. Location represents where you are and activity represents what you are doing.
As we will see in this article, and later articles in this series, location and activity go hand-in-hand and one can enrich the other. Knowing where you are (e.g. road) can help inform or confirm what you are doing (e.g. driving). Knowing what you are doing (e.g. stationary) can help inform or confirm where you are (e.g. at home).
We will further see that device health data from the OS, such as location mode, network conditions, battery levels, permissions and GPS availability, are necessary inputs to enrich movement data.
Before we dive deeper, let us consider a few common use cases and product experiences that developers want to build with movement data. Uber-for-X is one set of use cases where providers of product deliveries, local services and cab rides use movement data of providers to assign orders, track live movement of providers, get alerted when things go awry on the field and calculate mileage for billing and expenses. Live location sharing covers another set of popular use cases where friends share their live movement with each other when on the way to meet up.
Developers run into the BAR principle when working on accuracy of movement data.
BAR principle of movement
The BAR principle of movement (inspired by the CAP theorem in computer science) says that it is extremely difficult to simultaneously provide more than two out of the following three—Battery, Accuracy and Real-timeness.
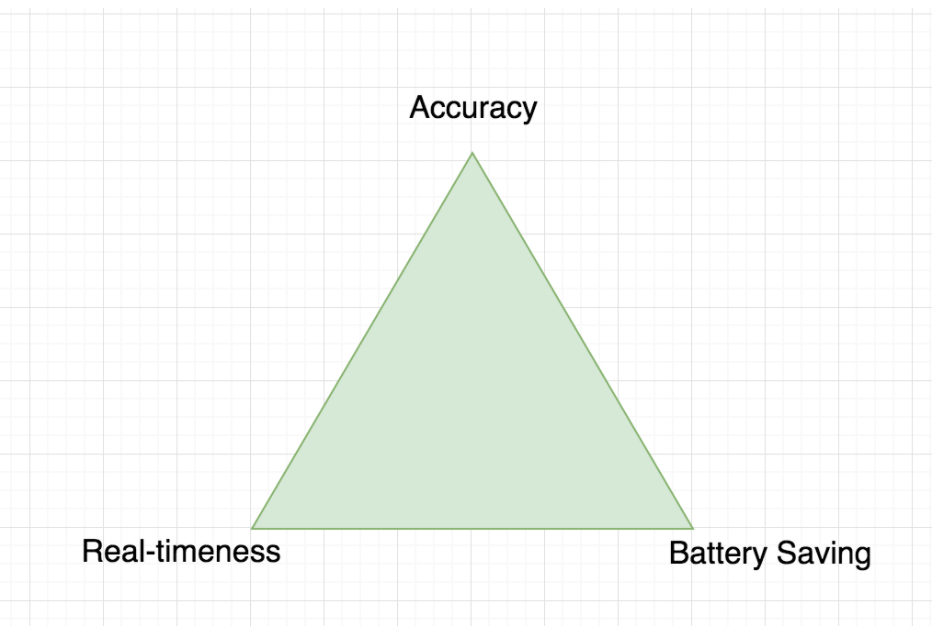
A system that optimizes for high accuracy and real-timeness will drain battery. Maximizing accuracy while minimizing battery will lose real-timeness of data on the server. Optimizing for real-timeness and saving battery will compromise on accuracy.
Let’s go one by one.
Battery and Accuracy: Movement data will be collected from the device at a high frequency and beamed to server in delayed batches. Techniques like exponential back-off may be used to delay collection of location data as well. However, this will compromise the real-timeness with which the server receives this data, by design. This blog post covers an interesting technique to manage the transmission frequency based on consumption on the server.
Accuracy and Real-timeness: Movement data will be collected from the device and transmitted to the server at a high frequency. High frequency of collection across sensors (GPS, Wi-Fi, Bluetooth, cell network, accelerometer, gyroscope and compass) and high frequency of transmission over the air (Wi-Fi, Bluetooth and cell data network) will cause high battery drain.
Battery and Real-timeness: Movement data will be collected at a low frequency and transmitted to the server immediately upon collection. This will result in an equivalent gap in the data due to the low frequency collection and compromise accuracy. This blog post talks about an interesting technique to control the configurations of a movement tracking SDK from the server.
Besides managing the trade-off between accuracy, real-timeness and battery, there is the eternal problem of sanitizing movement data. A variety of techniques and algorithms may be used. This blog post is a good primer for understanding a few techniques that filter locations to generate accuracy in real-time with efficient battery drain.
This article will revisit the techniques mentioned in the primer, add a few more popular techniques that come in handy, and take a look at how activity and device health are used to further improve results.
Before we dive deeper, let us introduce the three key considerations to trade-off—accuracy, real-timeness and battery.
Accuracy
Fused location data generated by the OS using location GPS, Wi-Fi, cell network and Bluetooth is frequently inaccurate. Similarly, fused activity data generated by the OS using activity from the accelerometer, gyroscope, compass and pedometer is frequently inaccurate. If you were to plot the raw location data on a map or view the timeline of activity data with no further processing, you would notice a number of discrepancies.
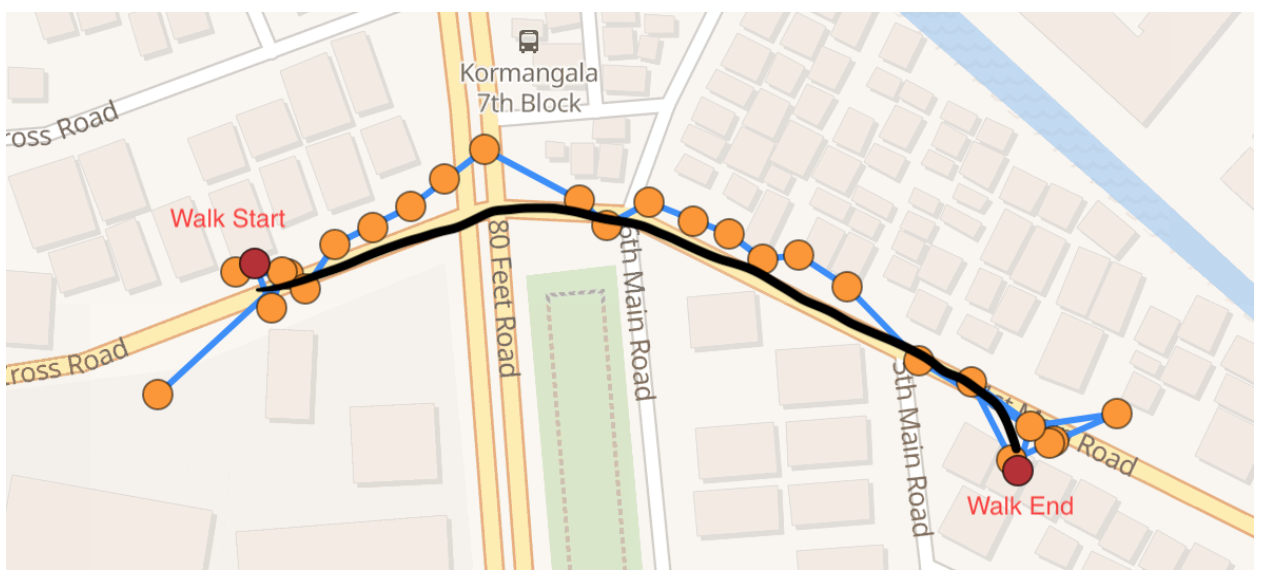
Real-life situations that cause such discrepancies include:
- Urban canyon: GPS signals bounce off tall buildings in an urban environment creating multipath signals. This may add random and significant errors in location data.
- Wi-Fi and Bluetooth: The OS may return erroneous locations with high confidence when inferences are based on Wi-Fi routers or Bluetooth beacons that have recently relocated.
- Tunnels and basements: GPS signals and cell networks may get jammed when the device is in a tunnel, basement, large structure or enclosed space.
Environment: Weather and visibility play a role in reducing GPS accuracy. - Low battery mode: Certain devices turn off GPS sensors in low battery mode and cause the accuracy to drop for a period of time.
- Airplane mode: Movement data from some sensors continues to get generated intermittently in airplane mode on most devices, leading to random dark patches.
- Flaky networks: Movement data needs to be collected as a time series to factor network outages that prohibit transmission of data to the server.
- Sink Problem: Besides GPS, Wi-Fi and Bluetooth, the OS uses cell network to determine location. A frequent problem with using cell tower triangulation to infer location is that the location of the mobile tower is returned as the device location. This typically happens when GPS signal is weak and user is passing by close to a mobile tower.
- Initial fix: When the device is switched on or location is enabled at a new place after a while, the OS takes additional time to generate an initial fix. The initial fix might have errors that get resolved after a few seconds thus resulting in outlier points at the start.
- Faraday cage: GPS signal strength becomes zero in certain electric trains with metalized chassis and windows. The GPS signal has no way to enter this train. This is called a Faraday cage. Such trains have repeaters in mobile zones to catch cell signals from outside the train. However, GPS signals are lost.
- Algorithm gaps: The OS uses machine learning models, probabilistic models and heuristics to infer location and activity after receiving a range of inputs from multiple sensors. These algorithms are non-deterministic and expect to have gaps that lead to inaccuracies.
Real-timeness
Not all use cases for movement data require accuracy in real-time. Here are a few examples of use cases that do:
- Movement-based alerts: Operations monitoring use cases generate communication with users & customers or trigger workflows based on speed, mileage, start/end of activity, long stops, geofences and many more inferences using movement data.
- Mileage-based billing: Mileage tracking use cases generate billing and receipts based on mileage of a ride immediately after it ends. Certain products might want to alert the customer when mileage-based billing exceeds a threshold.
- Product experience: Apps that show live location, trailing polyline, elapsed miles and live status of users in real-time want a smooth animation and beautiful experience.
- Safety: SOS calls, ambulances, school buses and other safety use cases want accurate live location and activity in real-time to save the day.
Battery
Collecting and transmitting movement data drains battery. This is a major concern with movement tracking across use cases. Infact, Android offers location modes that users may choose to trade off accuracy with battery.
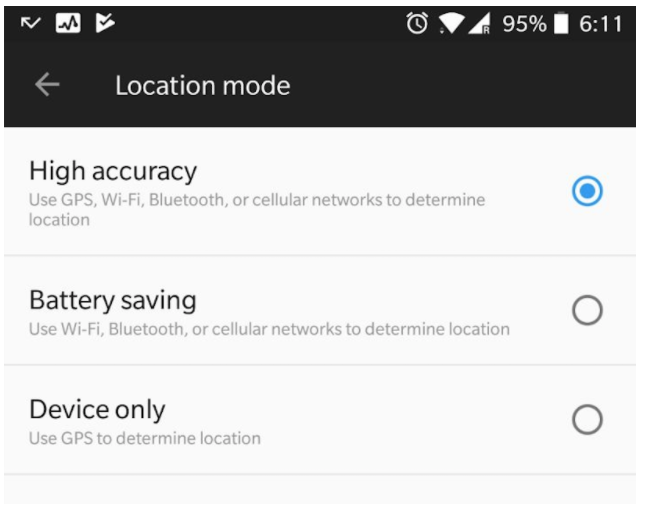
Use cases that involve drivers in a vehicle—truck, car, van—while being tracked may assume that the device is plugged in to a charging port and need not optimize for battery efficiency. However, use cases that require tracking of consumers, employees and contractors on-the-move will care about battery drain so the phone can last the day.
Balancing accuracy and real-timeness with battery requires a comprehensive characterization of operations that cause battery drain. For example, collecting data from certain sensors or OS APIs might drain significantly lesser battery than transmission of this data over the network. Similarly, sub-second accuracy might drain significantly higher battery than data collected at a minute of granularity. Precise instrumentation of battery cost for each movement generation operation will help inform algorithms. We will cover this topic in more detail in part 4 of the movement series.
Popular filters for location accuracy
Location filtering algorithms are applied to noisy location data to remove outliers and smoothen trajectories. Median, Kalman and particle filters are some of the popular filters used. We take a closer look at the median filter.
Median filter
Median filter works by approximating the actual location at a stop by the median of adjacent location points. The basic idea is that outlier locations will get eliminated by the median.
To illustrate, let’s say that a path is given by {(x0, t0), (x1, t1), (x2, t2),(x3, t3),........ }, where xi is the latitude/longitude coordinate of a location at time ti. Then the smoothened point at time ti is the median of N preceding points. N is 4 in this example.
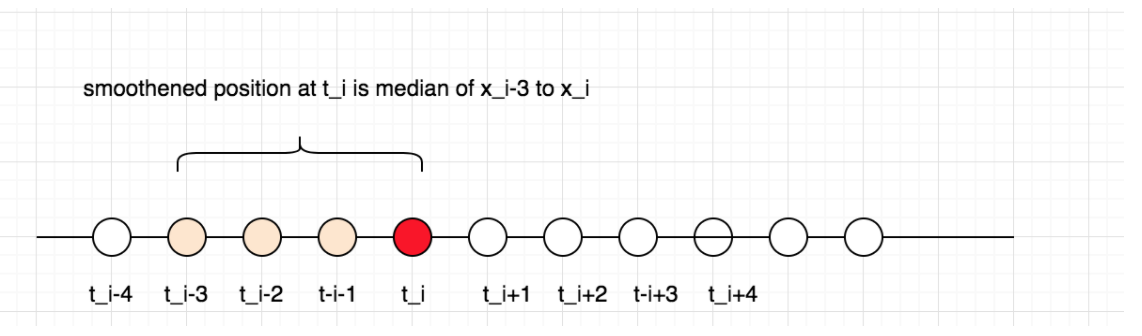
Here are the results of the smoothening of location data using the median filter.
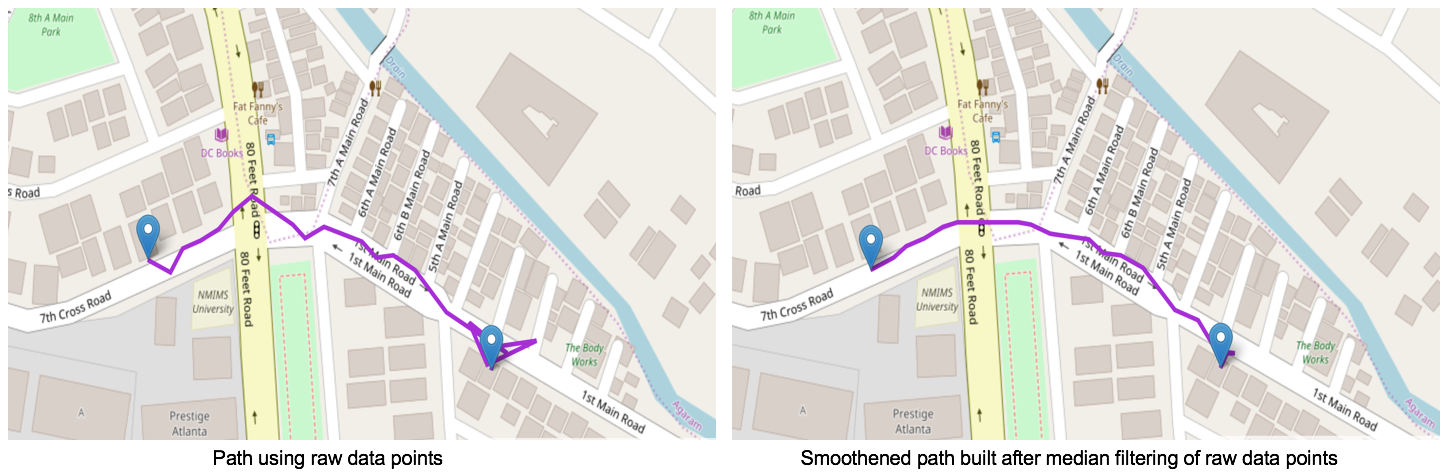
The median filter has two main limitations.
- It suffers from a lag. Changes in location are not immediately reflected in the output. To see this, consider a one dimensional case where numbers are coming in and we take the median of last 3 inputs. If the input sequence is {1, 2, 3, 5, 4} then the median output is {1, 2, 2, 3, 4}. Now suppose the next value is 10 so that the sequence becomes {1, 2, 3, 5, 4, 10}. In this case, the output sequence becomes {1, 2, 2, 3, 4, 5}. Now, if the next input is 11, the input sequence becomes {1,2,3,5,4,10,11} and the output becomes {1, 2, 2, 3, 4, 5, 10}. So there is a lag in the output compared to the input.
- The second problem is that the median filter can not be used to compute higher order properties of movement like speed.
Median filtering is a great candidate for filtering locations at a stop or dwell. If device sensors reveal that the user is stationary or dwelling at a place, the median filter can help improve the accuracy of the place where the user stopped.
Kalman and particle filters
Kalman and particle filters go one step further and estimate other variables of motion like velocity and orientation. This way, more accurate predictions can be made about the location and lag can be reduced. In that sense, Kalman and particle filters are more suited towards locations generated for drives, walks, cycling and others, while median filters work great for stops.
The basic idea for more advanced filters comes from two key insights:
- Instead of treating location coordinates as just plain numbers (like the way we do in Median filter), we can actually treat them as physical location and then make use of laws of motion in the underlying model.
- Inaccuracy in measurement can be modeled as a probability distribution which allows for application of probabilistic techniques to estimate actual values from measured values.
A distinction is made between measured values and real values to accomplish this. Note that we do not know what the real values are and can only see the measured values. The filter’s job is to predict the real values from the measured values. For example, consider a one dimensional case where an object is moving in a straight line and we are measuring its location. Let's assume that the real location and speed at time i are xi and si. Assume that the measured location is zi.The relation between the measured location and real location/speed can be written as
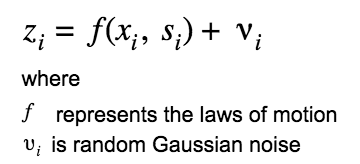
Similarly, the internal state of the model might be modeled by incorporating some noise.

In Kalman Filter, these two equations are solved together to get estimates for real location and speed of the moving object.
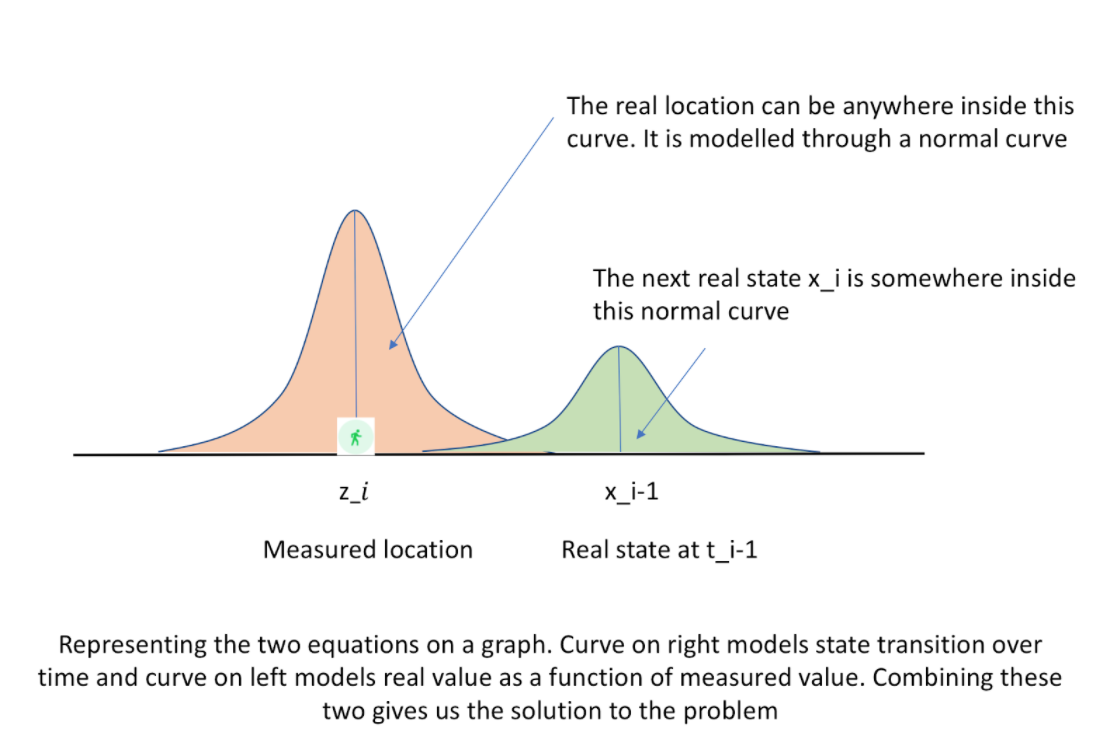
A primary limitation of Kalman filters is that the model has to be linear, viz. the equation between xi-1 and ximust be linear. Particle filter goes one step further and does away with the constraint of linear relationship as well as the constraint on noise to be Gaussian. This makes particle filter more generic but also computationally more expensive.
The estimated properties like velocity and orientation can also be used in a technique called dead reckoning. It is the process of calculating one's current position by using a previously determined position, and advancing that position based upon known or estimated speeds over elapsed time and course. Future blog posts will discuss these advanced filters and techniques.
Using map context to improve accuracy
Locations must be on the road when the user is driving. Locations recorded off the road when the user is driving may be assumed to be inaccurate to the extent of the displacement from the road and be corrected by shifting the location points to be on the road. This process is called map matching wherein a stream of location data is snapped to the most likely road that the user might be driving on.
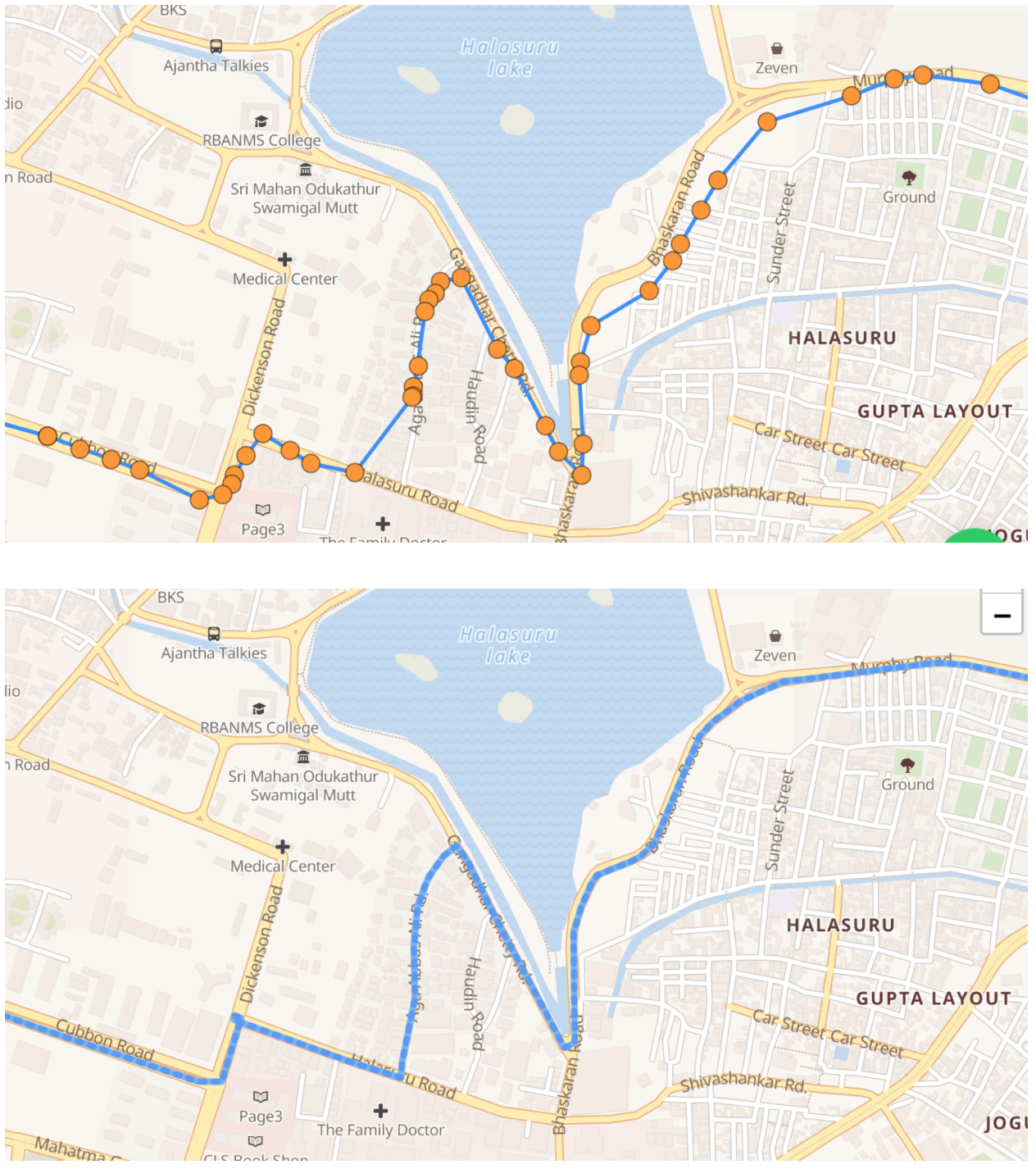
Location points are mapped to road and user’s actual path is predicted based on the assumption that they were driving
OSRM, based on OpenStreetMaps, may be used as an open data set for map matching. All leading map providers offer snap-to-road APIs in their product suites.
Map matching does not work reliably all the time. The accuracy of map matching depends on the accuracy of the primary location data generated. Significant inaccuracies may cause map APIs to suggest a route that is different from the one actually taken, especially when there are multiple plausible roads to choose from. Additional checks must be put in place to eliminate such scenarios. Flagging out significant deviations between raw location points and suggested routes might be a good start.
Using device health context to improve accuracy
Movement tracking is deeply tied to device health. In theory, everything works great in practice. In practice, nothing does. Assuming that the user’s device will be always working perfectly throughout the day is futile in the world of movement tracking. Frequent device health problems that affect movement accuracy are:
- Phone switched off: This might be purposeful or inadvertent due to battery drain, OS crash or hardware damage.
- App crashed: Apps with no crashes and software with no bugs are as real as unicorns.
- Patchy network: Data transmission to the server will be erratic or stalled if the network fails on the device or the server. Clients consuming movement data might see sudden jumps if not handled properly.
- Airplane and low battery modes: Many devices offer battery saving modes that reduce battery consumption by lowering performance of some services, including location and activity. Airplane modes also behave variably across devices with regard to location and activity. This will create gaps in movement data. Plotting the data on the map will show teleportation over buildings and roads.
This blog talks in detail about problems in movement tracking that arise from device health issues.
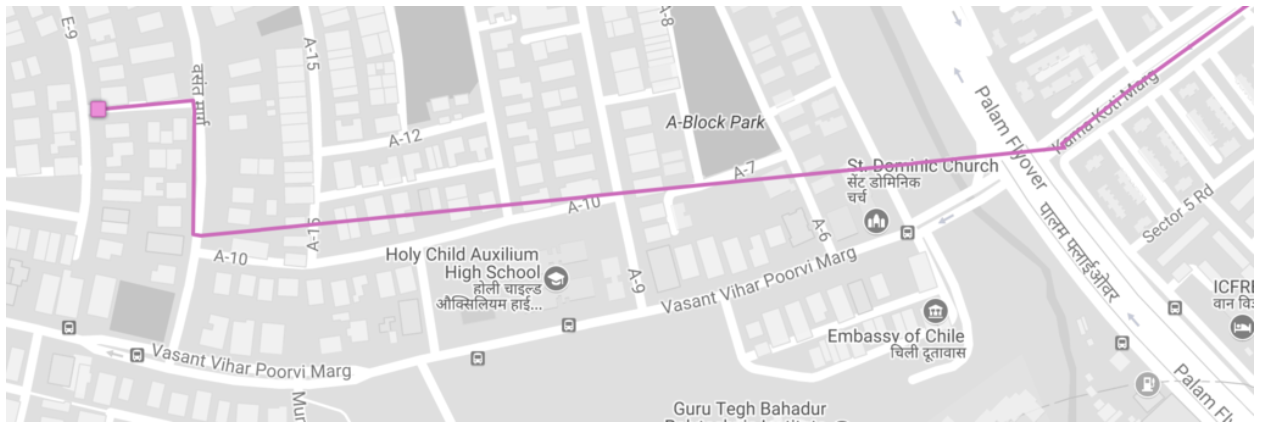
This problem may be solved by predicting the path that user might have taken between the points with large gaps. Map APIs may be used to do routing between points. However, the accuracy of routing will depend on the roads data for that area. You may additionally apply speed checks to ensure that the resulting route is plausible. For example, if the time gap between the two points is 30 seconds but map APIs resolve a route which is 1.5 Km long, the vehicle needs to travel at 3 Km per minute or 180 Km per hour. This path is highly unlikely and may be rejected.
Using activity context to improve accuracy
Movement is much more than location. While location tells us where the user is, activity tells us what the user is doing. Improvements through location filters may be further enhanced through algorithms using activity data. We saw some examples of this in the location filters where median filter was better suited for stops and Kalman was better suited for walks. Here are more examples:
- Be conservative about map matching for walks: Map matching may deliver incorrect results for walks. Walks on sidewalks might be aligned with the road, yet off it. Walks might happen on indoor (e.g. in a mall), semi-indoor (e.g. between buildings) or semi-outdoor (e.g. parks) paths or outdoor trails (e.g. national parks) with no corresponding routes on a map. While map matching will help improve walks alongside mapped roads, forcing walks to be on roads will reduce accuracy.
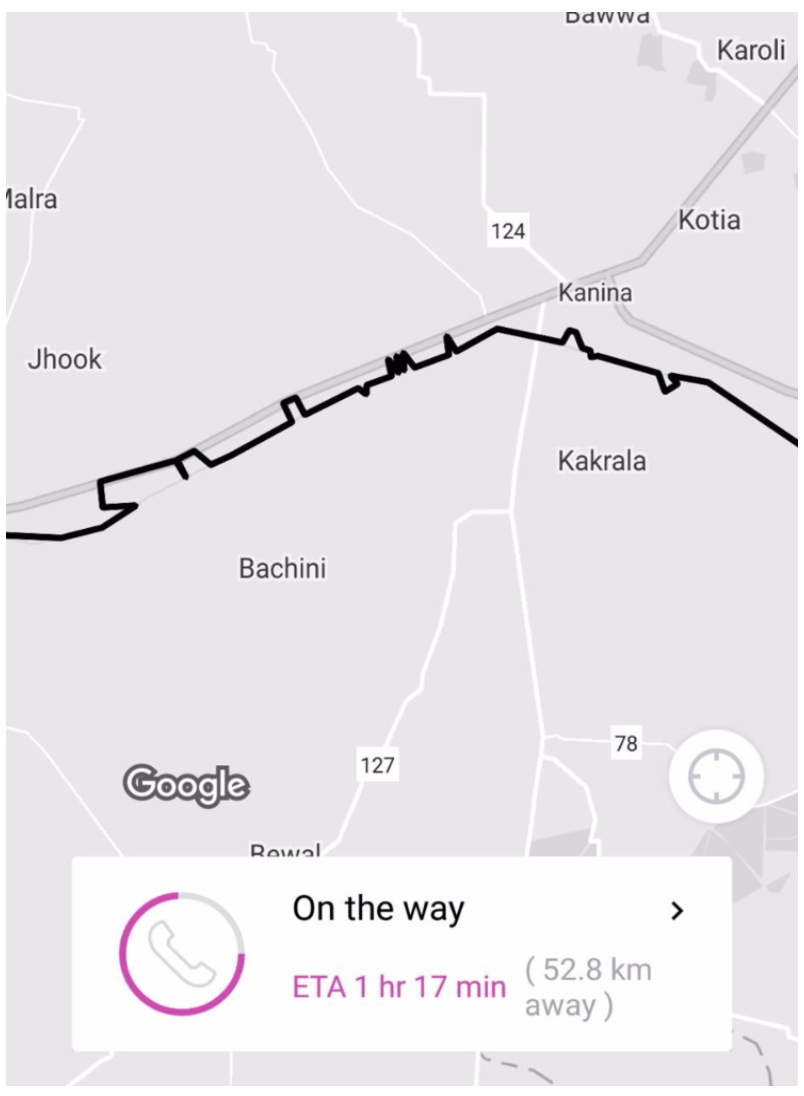
- Differentiate train tracks from roads: The OS will classify train rides as automotive due to accelerometer and speed data. However, not all automotive rides are drives on road. Map context comes handy in order to differentiate train from drives. Here is an example of a train ride if it were snapped to road instead of tracks.
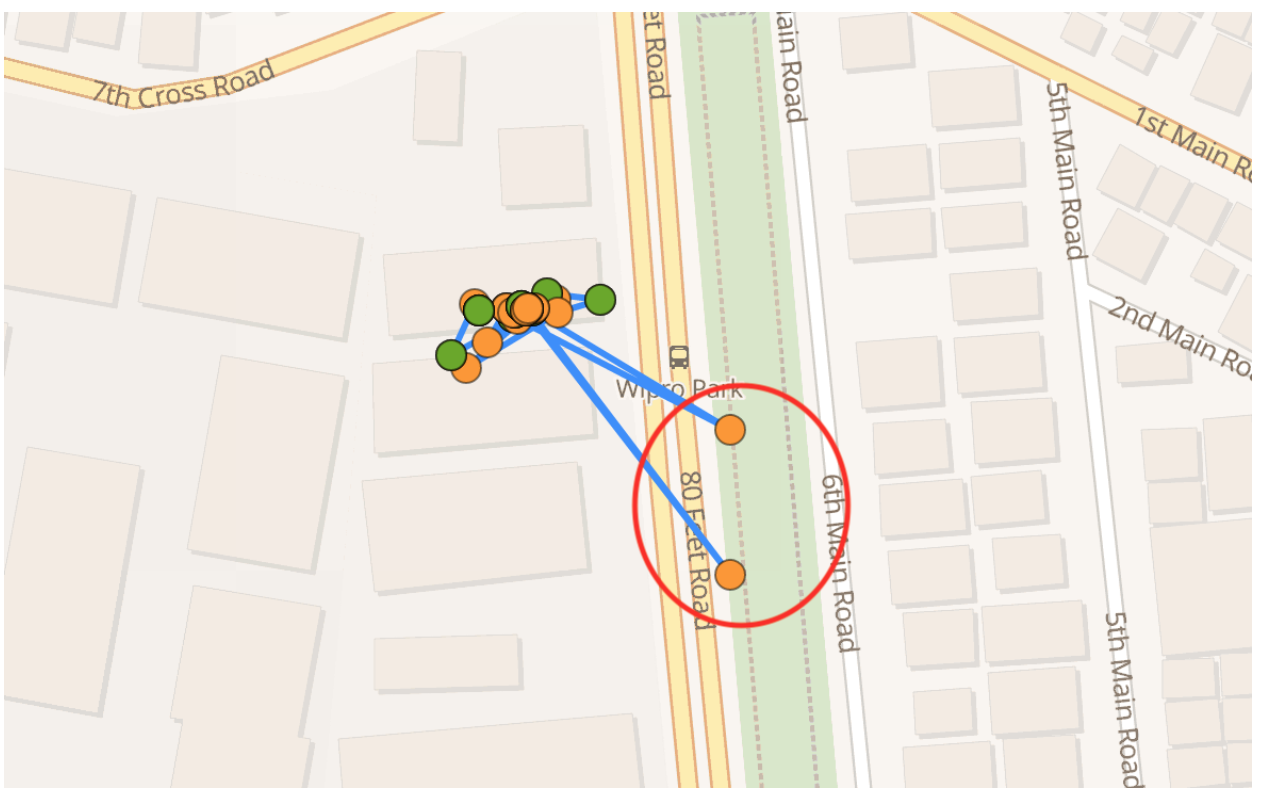
- Aggressively eliminate location changes at stops: Detection of long stops through activity detection might be more reliable compared to stop detection using intermittent location changes due to Wi-Fi or multipath GPS signals. Ignore sudden jumps in locations when the user’s activity is detected as a stop. It is unlikely that the change in location is due to actual movement. Here is an example of locations returned by the OS after fixed time thresholds while the user is at a stop.
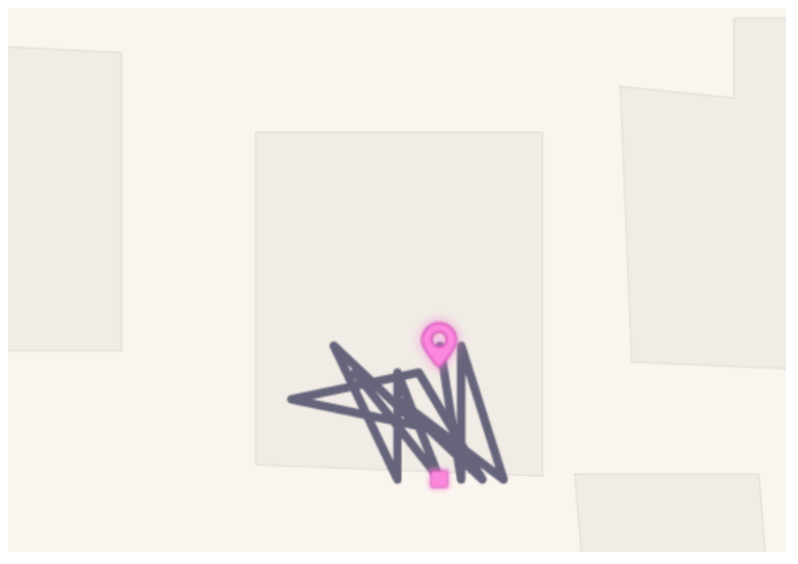
- Smoothen out indoor and semi-indoor walks: Raw location data for indoor and semi-indoor walks can be very erratic. Walks to the water cooler or dwells while speaking with someone on the phone will activate the pedometer and device inferences about activity. However, accompanying location changes may be taken with a pinch of salt. These walks may be treated as a stop at a place with the step count at the stop as the sum of step counts of all the walks at that stop.
There are many more examples where activity data helps inform or confirm location and vice versa. Hope these examples provide a useful background about the complexity of this problem. # Processing movement data in real-timeness Movement data rapidly explodes when tracking is configured for high accuracy. Consider a device that collects data at a rate of one location point every 5 seconds. This is equivalent to 720 location points per hour and 17280 location points in a day. Location collected at a rate of one point every 3 seconds translates to 1200 points per hour or 28800 location points in a day. Putting this data to use for real-time use cases requires smart processing. Let us consider the trade-offs between two extreme approaches to illustrate the complexity.
- Process one point at a time: This would mean that every location point is processed without the context of previous locations. While fast, it is restrictive and precludes map matching, for instance.
- Process all points at a time, say within activity segments: Consider an example with a 30 minute walk, followed by a 10 minute stop, followed by a 60 minute drive. We could process all locations of the walk in one processing request, then all locations of the stop and drive in respective processing requests. The advantage is that activity serves as a natural boundary for location data. If the walk was at a park, the context of those locations do not interfere with processing locations of the drive. However, there are problems with this approach:
- For activities that get longer in duration, you would either add resource overhead by processing a large number of points many times over to achieve real-timeness, or add latency by waiting for the activity to end before processing the points in a batch.
- Inaccuracy in activity detection can garble location data. Raw activity data from the OS is fragmented. It frequently happens that a 30 minute drive has 5 stationary segments in between. This will trigger processing of multiple short segments while contaminating the overall context for location processing. We will lose the opportunity to use location as a context to correct activity data.
Approach 2 has promise. Incremental processing of activity segments seems to work well.
Long activity segments may be split into shorter ones, then processed, and then recombined. Short activity segments may be eliminated with additional processing, and adjacent segments merged. Take care to split and merge these segments smoothly at the edge without breaking continuity.
The place where long segments are split or short segments are eliminated are great candidates for data enrichment. For example, a long drive might be broken at traffic lights and might be annotated as such. Short stops within a long drive might be high traffic segments that might be annotated within the drive without breaking it into two drives.
Conclusion
Developers building movement-aware applications generate movement data from the OS and consume movement data with map APIs. Processing movement data is often restricted to sanitizing location data using map matching.
Movement data includes location and activity. Making the two data sets work with each other is essential to get accurate inferences about where the user was and what she was doing. Device health data and map data provide useful context to further inform and confirm inferences made on movement data.
Furthermore, balancing battery, accuracy and real-timeness is a complex problem that requires software on the device, in the cloud and map interfaces. Movement data explosion makes it critical to thoughtfully generate, manage and consume this data.
Previous: Part 1—OS
Next: Part 3—Real-time

